On this page
Traders obsess over rules and parameters and barely glance at the data underneath them. That's backwards. A backtest is a simulation, and a simulation is only as truthful as its inputs. Feed it dirty candles and it will confidently report an edge that the clean market never offered — or bury a real one under noise. Data quality is the foundation everything else stands on, and in crypto that foundation is shakier than most people assume.
One bad print can fabricate a trade
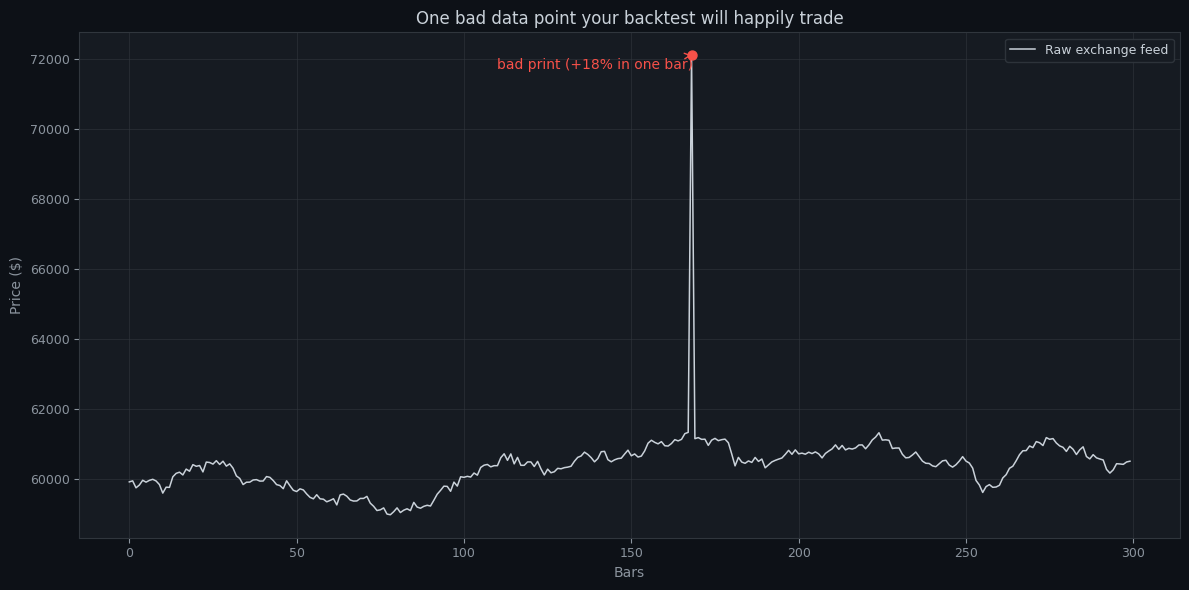
The chart shows a clean price series with one bad data point — a fat-finger trade, a feed glitch, a momentary wick to a nonsensical price. To you it's obviously an error. To your backtest engine it's a real candle: a breakout rule "buys" the spike, a stop-loss gets "hit" by it, a high-of-day calculation is poisoned by it. A single bad tick in a million candles can invent a winning trade that never existed, or trigger a catastrophic loss the live market would never have delivered. At scale, a handful of these can be the entire difference between a profitable and unprofitable backtest.
The quieter killers
Bad ticks are at least visible if you look. These are not:
- **Gaps and missing candles.** A feed that drops bars during high volatility — exactly when your strategy is most active — silently removes the hardest trades from your sample, flattering the result.
- **Survivorship bias.** Backtesting a basket of "major coins" using today's list bakes in the knowledge of which projects survived. The dead ones — the rug-pulls and the slow fades — are missing, so the universe you test looks far healthier than the one you'd actually have traded.
- **Inconsistent exchange data.** The same pair trades at slightly different prices and volumes on every venue. A backtest on Binance data for a strategy you'll run on Bybit is testing a different market — and for a volume-sensitive indicator like [VWAP](/blog/vwap-explained), a wrong volume column produces a wrong signal.
- **Restated or back-adjusted data.** Some historical feeds quietly correct old values. Trading on numbers that were revised after the fact is a cousin of [look-ahead bias](/blog/look-ahead-bias) — you're using information that didn't exist in real time.
How to sanity-check your data
You don't need a data-science team — a few cheap checks catch most of the damage:
- **Scan for impossible moves.** Flag any single-bar return beyond a sane threshold (say, more than a 30–40% move on a major in one candle) and inspect it. Most are bad prints.
- **Check for gaps.** Confirm the timestamps are evenly spaced with no missing bars, especially across volatile dates.
- **Sanity-check volume.** Zero-volume or wildly spiking volume bars corrupt any volume-weighted indicator.
- **Match the source to the target.** Test on data from the *same* exchange you intend to trade, over a window that includes the assets you'd actually have held at the time — not just the survivors.
- **Test across more than one regime.** A long, varied window dilutes the impact of any single bad patch and stops one clean bull run from flattering everything.
- **Compare two sources.** If a second exchange's candles disagree with your feed at the same timestamp by more than a hair, one of them is wrong — and it might be the one you backtested on.
The bottom line
Clean data won't make a bad strategy good, but dirty data will make a bad strategy *look* good — which is worse, because you'll fund it. Before you trust any backtest, trust its candles first — spend ten minutes scanning your data before you spend ten weeks trusting a strategy built on it. Noon Barbari fetches real, validated OHLCV per exchange so the backtest you run matches the market you'll trade — and a clean foundation is the cheapest edge in the whole process. It's also half the story of why live trading underperforms a backtest: garbage in, fiction out.
Try it on your own data
Every concept above is implemented in the platform. Backtest, walk-forward, paper-trade, then promote to live — same rule set, all stages.